查并集
查并集也是一种比较常用的算法,有必要掌握
下面文章转载于CSDN上的一篇博客,我觉得写的很详细,就把它贴出来吧
地址:https://blog.csdn.net/Hacker_ZhiDian/article/details/60965556
基础
对于今天要总结的算法,我想先通过一道题目来看一下:
假设现在我有一个任务交给你:要求你查看 id 为 x 和 id 为 y 的两个人是不是朋友,
在一开始我会在第一行中输入 3 个数字 n、m 、k。
n 是代表总人数。
接下来 m 行,每一行我会输入两个数字: Xi 、 Yi, 代表 id 为 Xi 和 id 为 Yi 的两个人是朋友(注意:朋友的朋友也是朋友),
接下来 k 行,每一行我也会输入两个数字: a 和 b ,代表我要你查询 id 为 a 和 id 为 b 的两个人是不是朋友,
如果这两个人是朋友,那么在一行中输出“yes”否则在一行中输出“no”。
数据约束:0 < n, m, k < 10000, 所有人的 id 都是正整数,并且 id 不会超过 n
样例输入:
7 5 4
1 3
2 4
3 4
1 4
5 6
1 4
2 3
2 5
6 7
样例输出:
yes
yes
no
no
在上面的题目中,如果没有说“朋友的朋友也是朋友”这句话,那么就好办了,我们直接用一个二维数组来记录每一组朋友的信息,然后进行筛选就行了。但是有了这句话,我们就不能简单的用二维数组来解决了。那么怎么解决呢?
首先,我们可以这样想,我们先把所有的人看成独立的群体,也就是说每个人的朋友只有他自己,那么这样的话一开始就有 n 个朋友圈,之后当题目数据输入的时候我们将输入的 id 所代表的的两个人所在的两个朋友圈合并成一个大的朋友圈,那么在这个合并之后的朋友圈中,所有的人两两都是朋友(朋友的朋友也是朋友),不断重复上面的合并过程,直到题目中给的 m 行的朋友对数据全部都合并完成。之后要判断两个人是不是朋友只需要判断他们是不是在同一个朋友圈里面就可以了。
我们用题目中给出的数据来模拟这个过程,先看代码:
#include <iostream>
using namespace std;
const int N = 10010;
int f[N];
/*
* 将表示朋友圈的数组初始化,即将所有人的“朋友祖先”都设置为自己的 id ,
* 于是就有了 n 个不同的朋友圈
*/
void init(int n) {
for(int i = 1; i <= n; i++) {
f[i] = i;
}
}
// 得到 id 为 v 的人的“朋友祖先”的 id
int getFriend(int v) {
if(f[v] == v) {
return v;
}
/*
* 如果发现“朋友祖先”不是自己,那么他肯定被合并到别的朋友圈里面去了,
* 那么继续调用这个函数来找这个朋友圈里面的“朋友祖先”,
* 并且在这个过程中将找到的人都设置为同一个“朋友祖先”(因为都在同一个朋友圈里面)
*/
return f[v] = getFriend(f[v]);
}
// 将两个人所在的两个朋友圈合并为一个朋友圈
void merge(int a, int b) {
int t1 = getFriend(a); // 得到左边的人的“朋友祖先”
int t2 = getFriend(b); // 得到右边的人的“朋友祖先”
/* 这里我们制定一个“靠左原则”:一旦发现两个人的“朋友祖先”不一样,
* 那么右边那个人的“朋友祖先”的“朋友祖先”设置为左边的人的“朋友祖先”,
* 当然,也可以制定“靠右原则”
*/
if(t1 != t2) {
f[t2] = t1;
}
}
int main() {
int n, m, k;
cin >> n >> m >> k;
int x, y;
init(n);
for(int i = 0; i < m; i++) {
cin >> x >> y;
merge(x, y);
}
for(int i = 0; i < k; i++) {
cin >> x >> y;
// 如果两个人的“朋友祖先”不相同,证明他们不在同一个朋友圈内,也就不是朋友
if(getFriend(x) != getFriend(y)) {
cout << "no" << endl;
} else {
cout << "yes" << endl;
}
}
return 0;
}
用图来模拟这一过程:

如果不能理解可以把例题数据带进去代码中自己模拟一遍就知道了,最后我们来看一下运行结果:
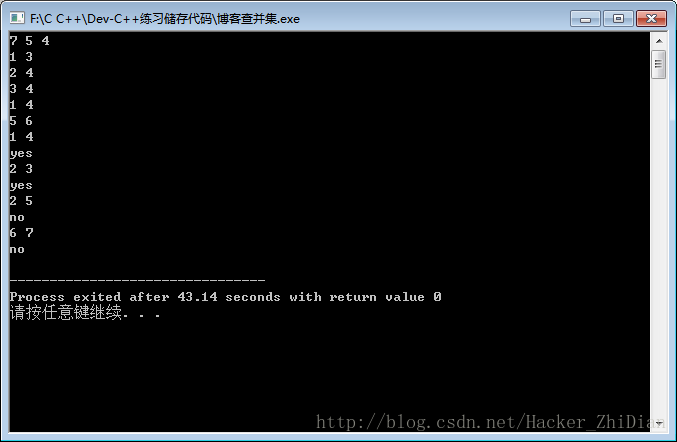
我们可以加一段代码来输出合并之后的数组情况:
#include <iostream>
using namespace std;
const int N = 10010;
int f[N];
/*
* 将表示朋友圈的数组初始化,即将所有人的“朋友祖先”都设置为自己的 id ,
* 于是就有了 n 个不同的朋友圈
*/
void init(int n) {
for(int i = 1; i <= n; i++) {
f[i] = i;
}
}
// 得到 id 为 v 的人的“朋友祖先”的 id
int getFriend(int v) {
if(f[v] == v) {
return v;
}
/*
* 如果发现“朋友祖先”不是自己,那么他肯定被合并到别的朋友圈里面去了,
* 那么继续调用这个函数来找这个朋友圈里面的“朋友祖先”,
* 并且在这个过程中将找到的人都设置为同一个“朋友祖先”(因为都在同一个朋友圈里面)
*/
return f[v] = getFriend(f[v]);
}
// 将两个人所在的两个朋友圈合并为一个朋友圈
void merge(int a, int b) {
int t1 = getFriend(a); // 得到左边的人的“朋友祖先”
int t2 = getFriend(b); // 得到右边的人的“朋友祖先”
/* 这里我们制定一个“靠左原则”:一旦发现两个人的“朋友祖先”不一样,
* 那么右边那个人的“朋友祖先”的“朋友祖先”设置为左边的人的“朋友祖先”,
* 当然,也可以制定“靠右原则”
*/
if(t1 != t2) {
f[t2] = t1;
}
}
int main() {
int n, m, k;
cin >> n >> m >> k;
int x, y;
init(n);
for(int i = 0; i < m; i++) {
cin >> x >> y;
merge(x, y);
}
/*
* 输出合并之后的数组情况
*/
for(int i = 1; i <= n; i++) {
if(i != 1) {
cout << " ";
}
cout << f[i];
}
cout << endl;
for(int i = 0; i < k; i++) {
cin >> x >> y;
// 如果两个人的“朋友祖先”不相同,证明他们不在同一个朋友圈内,也就不是朋友
if(getFriend(x) != getFriend(y)) {
cout << "no" << endl;
} else {
cout << "yes" << endl;
}
}
return 0;
}
结果:
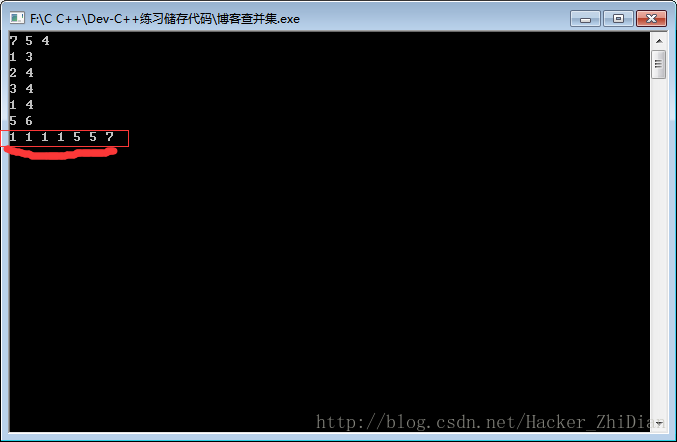
和我们在纸上模拟的结果一样,一共有三个朋友圈。
这个时候当数组某个位置的值等于其所在下标的时候,id 等于这个值的人就是这个朋友圈的“朋友祖先”, 有多少个“朋友祖先”就有多少个朋友圈。
Ok,其实上面说的这种算法思想就是查并集,其标准的描述也是通过树和森林来定义的:在一个森林中有很多棵不同的树,我们通过一些信息来将一些不同的分开的树合并成一棵大的树。在这道题目中,一开始森林中有 7 棵不同根节点的树,树的根节点在这道题目中就相当于“朋友祖先”(7 个朋友圈,每个朋友圈中只有一个人,即为他自己,也是每个朋友圈的“朋友祖先”),通过题中所给的信息不断合并朋友圈(合并森林中不同的树),合并结束之后森林中树的棵树或者不同的树的根节点的个数(“朋友祖先”的个数)就是朋友圈的个数。
好了,查并集的基本思想就总结到这里了,如果你想更深入的了解其优化,那么请往下看:
优化
我们在刚刚合并两个不同的朋友圈为一个大朋友圈的时候,我们制定了一个“靠左原则”,即为将右边的朋友圈作为子圈合并到左边那个朋友圈中,那么现在假设我们有这么两个朋友圈:
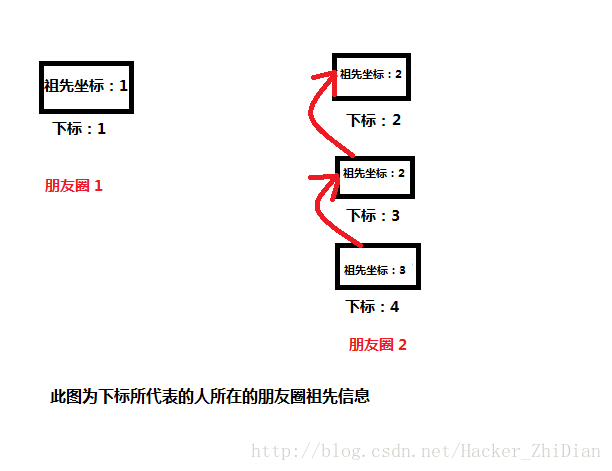
如果说现在我们要 合并下标为 1 的人所在的朋友圈 和 下标为 2 的人所在的朋友圈,按照我们刚刚定制的 “靠左原则”,此时我们应该把 朋友圈2 作为朋友圈1 的子圈并且合并到 朋友圈1 中。也就是执行一次我们上面代码中的 merge(1, 2) ,对那么合并之后的朋友圈就是:
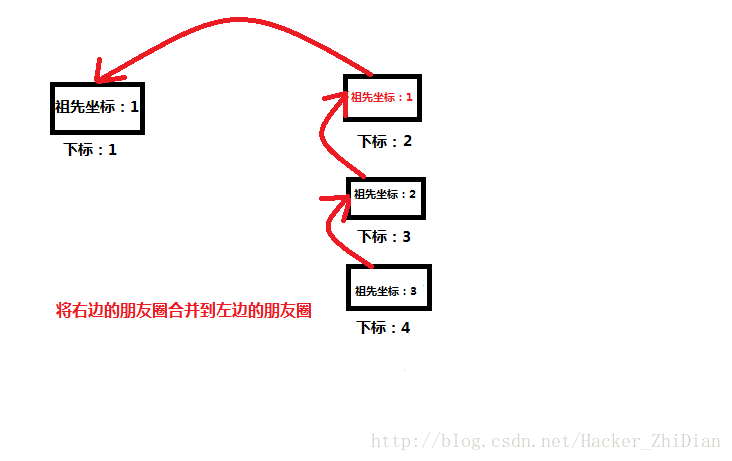
祖先坐标改变的部分我用红字表出来了。那么接下来,如果此时我要找出下标为 4 的人所在的朋友圈的祖先,因为此时两个朋友圈已经合并成一个了, 我们调用 getFriend(1) ,首先会查找到 3 ,然后是 2 ,然后是 1。也就是说此时我们要向上递归查找 3 次才能找到。这个效率相对来说不算高。那么问题在哪呢?其实是在我们合并两个朋友圈的时候定制的“靠左原则”。对于上面那种情况,我们明明应该将左边的朋友圈合并到右边的朋友圈效率才更高,此时合并的结果应该是:
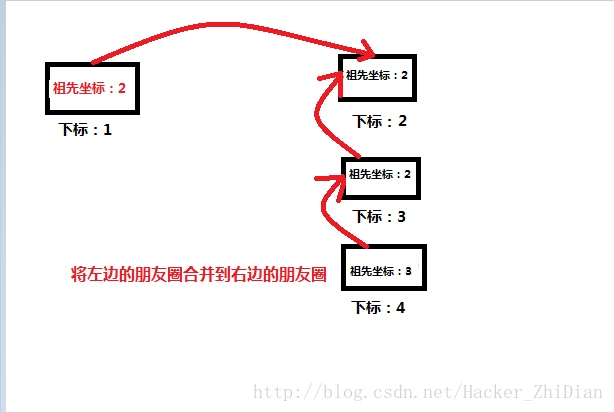
此时再查找下标为 4 的人所在的朋友圈就只需要向上递归 2 次就可以了。那么我们应该如何确定合并朋友圈的方式呢?可能到这里你已经想到了:将高度较小的那一个朋友圈作为子圈合并到高度较大的朋友圈。那么我们怎么获取每个朋友圈的高度呢?我们可以用一个数组来保存每个朋友圈的高度,在合并的时候比较两个朋友圈的高度来确定合并方式,合并完成之后调整一下合并后的朋友圈高度。 在上面代码的基础上,我们给出实现代码:
int high[N]; // 一个全局数组。保存每个朋友圈的高度,初始时都是 0
// 省略其他代码......
/**
* 将两个人所在的两个朋友圈合并为一个朋友圈
* 这里通过两个朋友圈的高度来决定合并方式
*/
void merge(int a, int b) {
int t1 = getFriend(a); // 得到左边的人的“朋友祖先”
int t2 = getFriend(b); // 得到右边的人的“朋友祖先”
// 两个人的“朋友祖先”不一样,合并两个朋友圈
if(t1 != t2) {
// 如果左边的朋友圈的高度大于右边的朋友圈的高度,
// 那么将右边的朋友圈合并到左边的朋友圈中
if (high[t1] > high[t2]) {
f[t2] = t1;
// 否则就把左边的朋友圈合并到右边的朋友圈中
} else {
f[t1] = t2;
// 如果当前两个朋友圈的高度相等,那么合并之后的朋友圈高度要加一
if (high[t1] == high[t2]) {
high[t2]++;
}
}
}
}
// 省略其他代码......
为了方便,我就只给出 merge 函数,因为只有 merge 函数改变了,其它函数都没变。
merge 函数里面有一句注释:// 如果当前两个朋友圈的高度相等,那么合并之后的朋友圈高度要加一 。这句话可能会有点难理解,看一幅图就知道了:
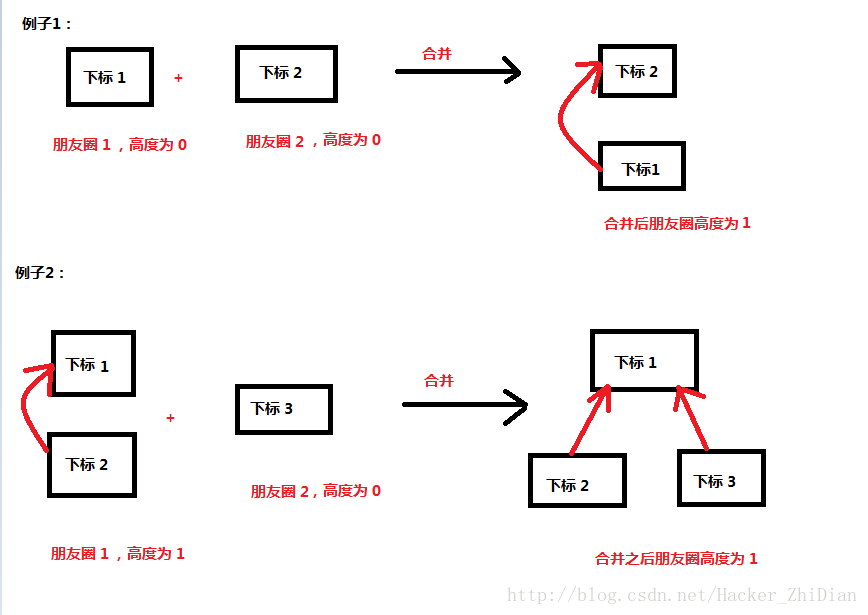
因为代码中设定的每个朋友圈初始高度为 0,,所以为了统一,图中也设置只有一个人的朋友圈高度为 0,这里注意一下。经过这样优化之后,我们的查并集的效率就很高了。
最后,我们来看一下程序的运行结果:
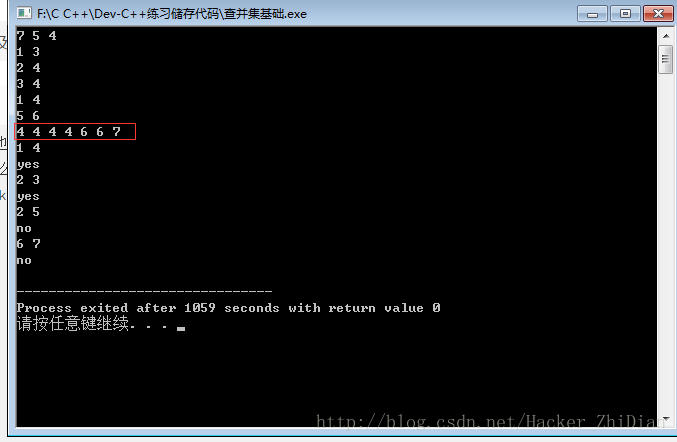
结果依然是 3 个朋友圈,并且之后判断两个人是否是同一个朋友圈的结果也是对的,但是每个朋友圈祖先的编号却和原来不一样,这其实是因为我们修改了合并两个朋友圈的方式,即从原来的“靠左原则”变成了“比较朋友圈高度原则”。
最后还是贴一下优化之后的完整代码:
#include <iostream>
using namespace std;
const int N = 10010;
int f[N];
int high[N]; // 保存每个朋友圈的高度,初始时都是 0
/*
* 将表示朋友圈的数组初始化,即将所有人的“朋友祖先”都设置为自己的 id ,
* 于是就有了 n 个不同的朋友圈
*/
void init(int n) {
for(int i = 1; i <= n; i++) {
f[i] = i;
}
}
// 得到 id 为 v 的人的“朋友祖先”的 id
int getFriend(int v) {
if(f[v] == v) {
return v;
}
/*
* 如果发现“朋友祖先”不是自己,那么他肯定被合并到别的朋友圈里面去了,
* 那么继续调用这个函数来找这个朋友圈里面的“朋友祖先”,
* 并且在这个过程中将找到的人都设置为同一个“朋友祖先”(因为都在同一个朋友圈里面)
*/
return f[v] = getFriend(f[v]);
}
/**
* 将两个人所在的两个朋友圈合并为一个朋友圈
* 这里通过两个朋友圈的高度来决定合并方式
*/
void merge(int a, int b) {
int t1 = getFriend(a); // 得到左边的人的“朋友祖先”
int t2 = getFriend(b); // 得到右边的人的“朋友祖先”
// 两个人的“朋友祖先”不一样,合并两个朋友圈
if(t1 != t2) {
// 如果左边的朋友圈的高度大于右边的朋友圈的高度,
// 那么将右边的朋友圈合并到左边的朋友圈中
if (high[t1] > high[t2]) {
f[t2] = t1;
// 否则就把左边的朋友圈合并到右边的朋友圈中
} else {
f[t1] = t2;
// 如果当前两个朋友圈的高度相等,那么合并之后的朋友圈高度要加一,
if (high[t1] == high[t2]) {
high[t2]++;
}
}
}
}
int main() {
int n, m, k;
cin >> n >> m >> k;
int x, y;
init(n);
for(int i = 0; i < m; i++) {
cin >> x >> y;
merge(x, y);
}
/*
* 输出合并之后的数组情况
*/
for(int i = 1; i <= n; i++) {
if(i != 1) {
cout << " ";
}
cout << f[i];
}
cout << endl;
for(int i = 0; i < k; i++) {
cin >> x >> y;
// 如果两个人的“朋友祖先”不相同,证明他们不在同一个朋友圈内,也就不是朋友
if(getFriend(x) != getFriend(y)) {
cout << "no" << endl;
} else {
cout << "yes" << endl;
}
}
return 0;
}
模板题
地址:https://nanti.jisuanke.com/t/T1260
宗教信仰
世界上有许多宗教,你感兴趣的是你学校里的同学信仰多少种宗教。你的学校有 nnn 名学生(0<n≤500000 < n \le 500000<n≤50000),你不太可能询问每个人的宗教信仰,因为他们不太愿意透露。但是当你同时找到 222 名学生,他们却愿意告诉你他们是否信仰同一宗教,你可以通过很多这样的询问估算学校里的宗教数目的上限。你可以认为每名学生只会信仰最多一种宗教。
输入格式
输入包括多组数据。每组数据的第一行包括 nnn 和 mmm,0≤m≤n(n−1)/20 \le m \le n(n-1)/20≤m≤n(n−1)/2,其后 mmm 行每行包括两个数字 iii 和 jjj,表示学生 iii 和学生 jjj 信仰同一宗教,学生被标号为 111 至 nnn。
输入以一行 n=m=0n = m = 0n=m=0 作为结束。
输出格式
对于每组数据,先输出它的编号(从 111 开始),接着输出学生信仰的不同宗教的数目上限。
输出时每行末尾的多余空格,不影响答案正确性
样例输入
10 9
1 2
1 3
1 4
1 5
1 6
1 7
1 8
1 9
1 10
10 4
2 3
4 5
4 8
5 8
0 0
样例输出
Case 1: 1
Case 2: 7
AC代码:
#include<iostream>
using namespace std;
const int N=50010;
int f[N];
int res=0;
void init(int n){
for(int i=1;i<=n;i++){
f[i]=i;
}
}
int getfriend(int v){
if(f[v]==v) return v;
else return f[v]=getfriend(f[v]);
}
void merge(int a,int b){
int x=getfriend(a);
int y=getfriend(b);
if(x!=y){
f[y]=x;
res++;
}
}
int main()
{
int n,m,k=0,x,y;
while(1){
res=0;
k++;
cin>>n>>m;
if(n==0&&m==0) break;
init(n);
for(int i=1;i<=m;i++){
cin>>x>>y;
merge(x,y);
}
cout<<"Case "<<k<<": ";
cout<<n-res<<endl;
}
return 0;
}
制作不易,您的赞助是我最大的动力,谢谢观看(owo)
 wechat
wechat alipay
alipay